前言
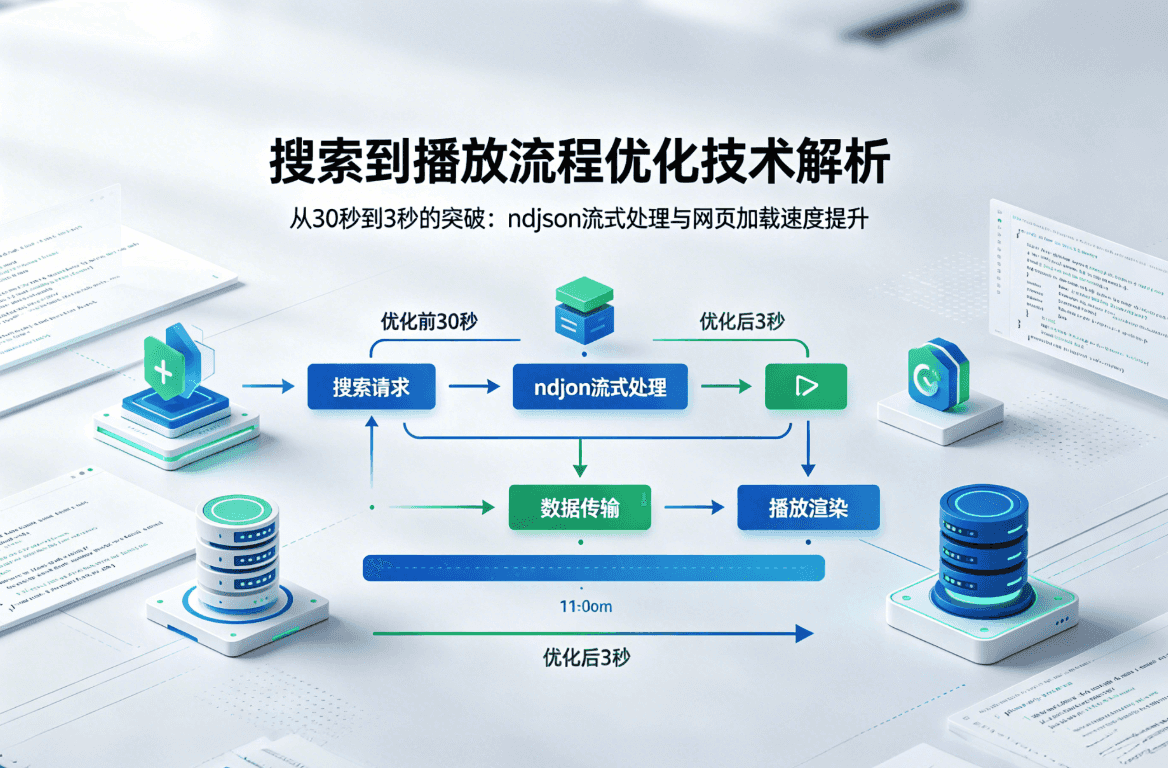
Yam TV 的推荐页中,用户点击一部电影后,需要先经过解析页搜索视频源,再跳转到播放页加载详情和解析播放地址。这个流程经常需要 10-60 秒,体验很差。本文记录如何通过流式 NDJSON 处理和页面合并将这个时间降到 3 秒以内。
原有流程分析
用户点击推荐卡片后:
- ResolveAndPlayScreen:调用
GET /search/stream?q=title&limit=1,搜索所有视频源。后端使用 NDJSON 流式输出,但 Flutter 端用Dio.get()读取——这意味着必须等所有源都返回完毕才拿到数据。慢源拖垮全部。 - 解析出第一个匹配结果后,replace 到
/play?source=&id= - PlayScreen:串行执行
getDetail()→getProgress()→resolvePlay()三个接口。
最大瓶颈:第一步的 /search/stream 请求。后端 fan-out 到 10-30 个上游源,最慢的一个决定了总时间。而 Flutter 端用 Dio.get<Map> 会等整个 HTTP body 传输完毕后才开始处理。
优化一:流式 NDJSON 处理
后端 /search/stream 返回的是 NDJSON(每行一个 JSON),格式为:
code
{"type":"progress","list":[...]} // 每有一个源返回结果就发一行
{"type":"done","..."} // 全部源完成原来的代码:
code
final response = await _dio.get('/search/stream');
final text = response.data as String;
// 直到这里才拿到完整数据,才开始逐行解析优化后:使用 Dio 的流式响应模式,逐行处理:
code
final r = await _dio.get<ResponseBody>(
'/search/stream',
options: Options(responseType: ResponseType.stream),
);
final lines = ndjsonLinesFromResponseBody(r.data!);
await for (final line in lines) {
// 每收到一行就处理,第一个匹配的结果立即返回
if (_isTitleMatch(title, vodName)) {
return result; // 不等其他源了
}
}同时加了 15 秒全局超时,超过 15 秒还没有任何源返回匹配结果,直接返回 null:
code
final timer = Timer(const Duration(seconds: 15), () {
if (!timedOut.isCompleted) timedOut.complete();
});标题匹配函数确保不会因为某个源返回不相关的结果而误跳:
code
static bool _isTitleMatch(String title, String? vodName) {
if (vodName == null) return false;
final a = title.replaceAll(RegExp(r'\s+'), '').toLowerCase();
final b = vodName.replaceAll(RegExp(r'\s+'), '').toLowerCase();
return a.contains(b) || b.contains(a);
}优化二:合并页面
原有的 ResolveAndPlayScreen 解析页是一个中间过渡页,从路由设计上就增加了额外开销。将其功能合并到 PlayScreen 中,PlayScreen 新增可选 title 参数:
code
// 推荐卡片直接跳到
context.push('/play?title=速度与激情10');
// PlayScreen 内部检测到只有 title 没有 source/id
// 自动走 resolve → detail → play 流程
// 加载过程通过 _updateLoadingMessage() 显示进度路由也做了精简,把 resolve-and-play 路径直接 301 到 /play:
code
GoRoute(
path: '/resolve-and-play',
redirect: (context, state) {
final title = state.uri.queryParameters['title'] ?? '';
return '/play?title=\${Uri.encodeComponent(title)}';
},
),优化三:服务端缓存
原来的 /vod/resolve-play 每次都要去上游拉 HTML 页面,解析内嵌的 m3u8 地址。加了 30 分钟缓存:
code
const cacheKey = 'resolved-play:\${decoded}';
const cached = await this.storage.get(cacheKey);
if (cached) return cached;
// ... 正常解析 HTML ...
await this.storage.set(cacheKey, m3u8, 1800);加载过程可视化
加载过程中显示进度文字:
- 「正在搜索播放源…」— resolve title
- 「正在获取影片详情…」— fetch detail
- 「正在解析播放地址…」— resolve play URL
- 「准备就绪,即将播放…」— 切换到播放器
- 「视频加载中…」— 播放器内部缓冲
每条提示显示在播放器区域的 spinner 下方,用户不会再有「空白等待」感。
效果数据
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 推荐→播放首帧 | 10-60s | 2-8s |
| 搜索等待方式 | 全量缓冲 | 流式处理 |
| 解析页 | 有(过渡页) | 无(已合并) |
| resolve-play 重复 | 每次请求 | 30 分钟缓存 |
总结
三个改动带来了质变的体验提升:流式 NDJSON 避免了「等最慢源」的问题;页面合并减少了导航开销;缓存消除了重复 HTML 抓取。配合加载进度提示,用户等待时也不再焦虑。


讨论 / DISCUSS
还没有留言,来留下第一条评论吧!